Batch processing¶
This article provides information about running OCRmyPDF on multiple files or configuring it as a service triggered by file system events.
Batch jobs¶
Consider using the excellent GNU Parallel to apply OCRmyPDF to multiple files at once.
Both parallel and ocrmypdf will try to use all available
processors. To maximize parallelism without overloading your system with
processes, consider using parallel -j 2 to limit parallel to running
two jobs at once.
This command will run ocrmypdf on all files named *.pdf in the
current directory and write them to the previously created output/
folder. It will not search subdirectories.
The --tag argument tells parallel to print the filename as a prefix
whenever a message is printed, so that one can trace any errors to the
file that produced them.
parallel --tag -j 2 ocrmypdf '{}' 'output/{}' ::: *.pdf
OCRmyPDF automatically repairs PDFs before parsing and gathering information from them.
Directory trees¶
This will walk through a directory tree and run OCR on all files in place, and printing each filename in between runs:
find . -printf '%p\n' -name '*.pdf' -exec ocrmypdf '{}' '{}' \;
Alternatively, with a Docker container and streaming the file through standard input and output:
find . -name '*.pdf' -print0 | xargs -0 | while read pdf; do
pdfout=$(mktemp)
docker run --rm -i jbarlow83/ocrmypdf - - <$pdf >$pdfout && cp $pdfout $pdf
done
This only runs one ocrmypdf process at a time. This variation uses
find to create a directory list and parallel to parallelize runs
of ocrmypdf, again updating files in place.
find . -name '*.pdf' | parallel --tag -j 2 ocrmypdf '{}' '{}'
In a Windows batch file, use
for /r %%f in (*.pdf) do ocrmypdf %%f %%f
Sample script¶
This user contributed script also provides an example of batch processing.
#!/usr/bin/env python3
# SPDX-FileCopyrightText: 2016 findingorder <https://github.com/findingorder>
# SPDX-License-Identifier: MIT
from __future__ import annotations
# This script must be edited to meet your needs.
import logging
import os
import sys
from pathlib import Path
import ocrmypdf
# pylint: disable=logging-format-interpolation
# pylint: disable=logging-not-lazy
script_dir = Path(__file__).parent
if len(sys.argv) > 1:
start_dir = Path(sys.argv[1])
else:
start_dir = Path('.')
if len(sys.argv) > 2:
log_file = Path(sys.argv[2])
else:
log_file = script_dir.with_name('ocr-tree.log')
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s %(message)s',
filename=log_file,
filemode='a',
)
ocrmypdf.configure_logging(ocrmypdf.Verbosity.default)
for filename in start_dir.glob("**/*.py"):
logging.info(f"Processing {filename}")
result = ocrmypdf.ocr(filename, filename, deskew=True)
if result == ocrmypdf.ExitCode.already_done_ocr:
logging.error("Skipped document because it already contained text")
elif result == ocrmypdf.ExitCode.ok:
logging.info("OCR complete")
logging.info(result)
Synology DiskStations¶
Synology DiskStations (Network Attached Storage devices) can run the Docker image of OCRmyPDF if the Synology Docker package is installed. Attached is a script to address particular quirks of using OCRmyPDF on one of these devices.
This is only possible for x86-based Synology products. Some Synology products use ARM or Power processors and do not support Docker. Further adjustments might be needed to deal with the Synology’s relatively limited CPU and RAM.
#!/bin/env python3
# SPDX-FileCopyrightText: 2017 Enantiomerie
# SPDX-License-Identifier: MIT
"""Example OCRmyPDF for Synology NAS"""
from __future__ import annotations
# This script must be edited to meet your needs.
import logging
import os
import shutil
import subprocess
import sys
import time
# pylint: disable=logging-format-interpolation
# pylint: disable=logging-not-lazy
script_dir = os.path.dirname(os.path.realpath(__file__))
timestamp = time.strftime("%Y-%m-%d-%H%M_")
log_file = script_dir + '/' + timestamp + 'ocrmypdf.log'
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s %(message)s',
filename=log_file,
filemode='w',
)
start_dir = sys.argv[1] if len(sys.argv) > 1 else '.'
for dir_name, _subdirs, file_list in os.walk(start_dir):
logging.info(dir_name)
os.chdir(dir_name)
for filename in file_list:
file_stem, file_ext = os.path.splitext(filename)
if file_ext != '.pdf':
continue
full_path = os.path.join(dir_name, filename)
timestamp_ocr = time.strftime("%Y-%m-%d-%H%M_OCR_")
filename_ocr = timestamp_ocr + file_stem + '.pdf'
# create string for pdf processing
# the script is processed as root user via chron
cmd = [
'docker',
'run',
'--rm',
'-i',
'jbarlow83/ocrmypdf',
'--deskew',
'-',
'-',
]
logging.info(cmd)
full_path_ocr = os.path.join(dir_name, filename_ocr)
with open(filename, 'rb') as input_file, open(
full_path_ocr, 'wb'
) as output_file:
proc = subprocess.run(
cmd,
stdin=input_file,
stdout=output_file,
stderr=subprocess.PIPE,
check=False,
text=True,
errors='ignore',
)
logging.info(proc.stderr)
os.chmod(full_path_ocr, 0o664)
os.chmod(full_path, 0o664)
full_path_ocr_archive = sys.argv[2]
full_path_archive = sys.argv[2] + '/no_ocr'
shutil.move(full_path_ocr, full_path_ocr_archive)
shutil.move(full_path, full_path_archive)
logging.info('Finished.\n')
Huge batch jobs¶
If you have thousands of files to work with, contact the author. Consulting work related to OCRmyPDF helps fund this open source project and all inquiries are appreciated.
Hot (watched) folders¶
Watched folders with watcher.py¶
OCRmyPDF has a folder watcher called watcher.py, which is currently included in source distributions but not part of the main program. It may be used natively or may run in a Docker container. Native instances tend to give better performance. watcher.py works on all platforms.
Users may need to customize the script to meet their requirements.
pip3 install ocrmypdf[watcher]
env OCR_INPUT_DIRECTORY=/mnt/input-pdfs \
OCR_OUTPUT_DIRECTORY=/mnt/output-pdfs \
OCR_OUTPUT_DIRECTORY_YEAR_MONTH=1 \
python3 watcher.py
Environment variable |
Description |
|---|---|
OCR_INPUT_DIRECTORY |
Set input directory to monitor (recursive) |
OCR_OUTPUT_DIRECTORY |
Set output directory (should not be under input) |
OCR_ARCHIVE_DIRECTORY |
Set archive directory for processed originals (should not be under input, requires |
OCR_ON_SUCCESS_DELETE |
This will delete the input file if the exit code is 0 (OK) |
OCR_ON_SUCCESS_ARCHIVE |
This will move the processed orignal file to |
OCR_OUTPUT_DIRECTORY_YEAR_MONTH |
This will place files in the output in |
OCR_DESKEW |
Apply deskew to crooked input PDFs |
OCR_JSON_SETTINGS |
A JSON string specifying any other arguments for |
OCR_POLL_NEW_FILE_SECONDS |
Polling interval |
OCR_LOGLEVEL |
Level of log messages to report |
One could configure a networked scanner or scanning computer to drop files in the watched folder.
Watched folders with Docker¶
The watcher service is included in the OCRmyPDF Docker image. To run it:
docker run \
-v <path to files to convert>:/input \
-v <path to store results>:/output \
-v <path to store processed originals>:/archive \
-e OCR_OUTPUT_DIRECTORY_YEAR_MONTH=1 \
-e OCR_ON_SUCCESS_ARCHIVE=1 \
-e OCR_DESKEW=1 \
-e PYTHONUNBUFFERED=1 \
-it --entrypoint python3 \
jbarlow83/ocrmypdf \
watcher.py
This service will watch for a file that matches /input/\*.pdf,
convert it to a OCRed PDF in /output/, and move the processed
original to /archive. The parameters to this image are:
Parameter |
Description |
|---|---|
|
Files placed in this location will be OCRed |
|
This is where OCRed files will be stored |
|
Archive processed originals here |
|
Define environment variable |
|
Define environment variable |
|
Define environment variable |
|
This will force |
This service relies on polling to check for changes to the filesystem. It may not be suitable for some environments, such as filesystems shared on a slow network.
A configuration manager such as Docker Compose could be used to ensure that the service is always available.
# SPDX-FileCopyrightText: 2022 James R. Barlow
# SPDX-License-Identifier: MIT
---
version: "3.3"
services:
ocrmypdf:
restart: always
container_name: ocrmypdf
image: jbarlow83/ocrmypdf
volumes:
- "/media/scan:/input"
- "/mnt/scan:/output"
environment:
- OCR_OUTPUT_DIRECTORY_YEAR_MONTH=0
user: "<SET TO YOUR USER ID>:<SET TO YOUR GROUP ID>"
entrypoint: python3
command: watcher.py
Caveats¶
watchmedomay not work properly on a networked file system, depending on the capabilities of the file system client and server.This simple recipe does not filter for the type of file system event, so file copies, deletes and moves, and directory operations, will all be sent to ocrmypdf, producing errors in several cases. Disable your watched folder if you are doing anything other than copying files to it.
If the source and destination directory are the same, watchmedo may create an infinite loop.
On BSD, FreeBSD and older versions of macOS, you may need to increase the number of file descriptors to monitor more files, using
ulimit -n 1024to watch a folder of up to 1024 files.
Alternatives¶
On Linux, systemd user services can be configured to automatically perform OCR on a collection of files.
Watchman is a more powerful alternative to
watchmedo.
macOS Automator¶
You can use the Automator app with macOS, to create a Workflow or Quick
Action. Use a Run Shell Script action in your workflow. In the context
of Automator, the PATH may be set differently your Terminal’s
PATH; you may need to explicitly set the PATH to include
ocrmypdf. The following example may serve as a starting point:
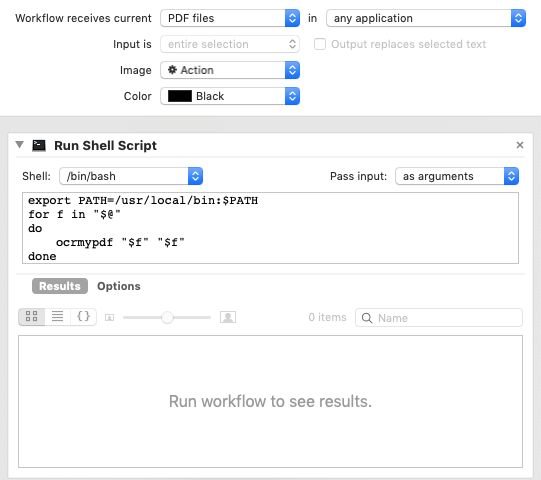
You may customize the command sent to ocrmypdf.